Designing the Microservices over Space-Based Architecture
- Immediate Solution for Database Bottleneck Issues in Monolith Migration Projects
Being an early adopter and promoter of Microservices, like many other technological enthusiasts who jumped on this bandwagon, I also finally ended up in database bottleneck issues within no time. The primary reason was that most of the projects were monolith migrations, and it became necessary to maintain the single database in its original state for the initial release. And the end result — even though web servers displayed a massive performance boost, bottleneck eventually relocated to the database layer.
The migration did work wonders for the read-only microservices connected to the respective read-only database replications. Naturally the microservices should be designed with their own databases by carefully designing the bounded context. But in reality, architects were compelled to redesign monolith application into microservices within a limited timeframe. The initial plan may be to make use of on-demand Elastic Cloud Servers or Containers which help to dynamically spin off new instances in milliseconds. As a result, they were left with no other choices but to delay the redesign and decomposition of the database until a later phase.
Keeping the above scenario in mind, lets analyze what are our best options to jump start with least implications as possible. Database replication along with CQRS design pattern is a good choice but not much helpful in a high-volume application where write counts are relatively high. Database Sharding help to some extent but the overhead comes with it makes that a non-optimal solution though.
What is Space-Based Architecture?
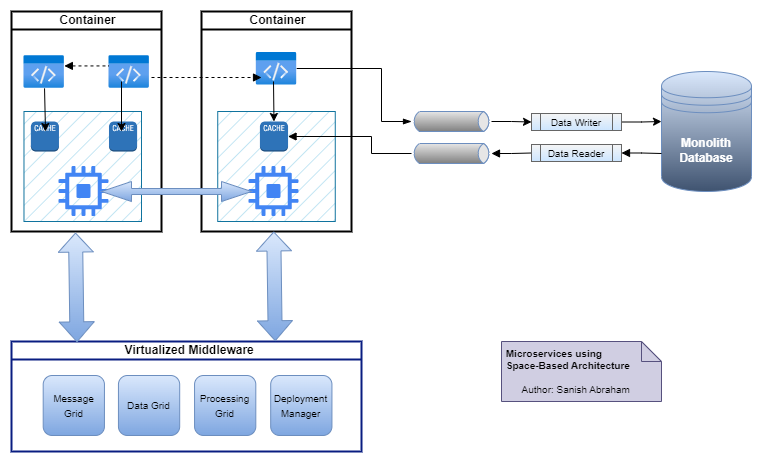
This is an architectural style where multiple processing units running in parallel with its own in-memory data grid synchronized using a virtualized middleware. Data updates will be asynchronously sent to the database using persistent message queues. Processing units can be dynamically started up and shut down depending on the concurrent user load. Skipping direct database access in a web request life cycle helps to achieve peak level of scalability and elasticity.
Each processing unit has business logic components which read/write data to its own in-memory cache which were synchronized immediately between all the instances by the data replication engine. Data pumps are responsible for eventual consistency of the data between the in-memory cache and the database. This asynchronous process is implemented through messaging queues from where Data Writers accept data and update the central database. Data Readers on the other hand read data from the database and updating to the processing units.
Virtualized middleware comprising various elements like Data Grid, Messaging Grid, Processing Grid and Deployment Manager. All these components have various responsibilities which may include request handling, load balancing, managing distributed cache, starting up and shutting down of processing units, request mediation and orchestration.
Microservices and Transactional Sagas
Microservice by definition is a loosely coupled, fine grained modular service with its own bounded context. Each service should have its own database carefully designed around the domain. The service being the owner of the update in that domain context, should be controlling all the writes to its database.
Transactional saga pattern manages distributed transaction across multiple services defining the communication and coordination between them. This can be implemented with a central orchestrator which manages the transaction by calling each participant service for successfully completing the required task. Orchestrator service is also responsible to execute the compensating transaction in case of a failure during its course to retain the original state in all services.
Choreography pattern on the other hand does not require any central coordinator, instead each participant service has the responsibility to finish the workflow. Even though this may avoid the risk of single point of failure in orchestration pattern, in reality it could lead to complex state management and require multiple communication paths to manage boundary errors.
Data Decoupling
Pulling apart data from a big monolith DB to smaller service domain context database is a high-risk process from the business point of view. This potential application-disruptive process needs to be handled with utmost care and detailed planning. The preliminary phase is to identify the service boundaries along with their related database entities and dependencies.
Once the microservices are defined and created, instead of splitting up the database straight away, first determine all the data tables involved within the bounded context. Then, use a space-based architecture to set up in-memory data grids and load these tables into a replicated cache. In addition, transfer stored procedures and any other SQL-specific application logic to the business layer.
However, rewriting any DB script-level transactions that involve tables from other service domains and moving the logic to the service level should be deferred until other domains are also moved to their corresponding microservices. And later it will be implemented as distributed transaction using the transactional sagas as mentioned above.
There are several other crucial factors influence the implementation of transactional sagas including synchronous vs asynchronous messaging, atomic vs eventual consistency etc. This is an important area which needs a dedicated space for a detailed explanation. I would like to write a separate article on this interesting and challenging area of architecture design which includes various sagas and their usecases.
Final Words
The optimal method for developing a microservice is to start from scratch and build a new database as well. However, when it comes to migrating from a monolith to microservices, a better option is to determine the necessary database entities and associated business logic and move them to an in-memory cache grid rather than immediately partitioning the existing database. Based on my experience, space-based architecture is the seamless way of transition which ensures scalability, availability and consistency with minimal effort.
We all know that a one-fit-all solution never exists in software architecture and it is the responsibility of the architect to pick an ideal solution after carefully analyzing the entire system. There is no single best solution, but one with the least side effects. Picking that one is the art of architecting :)
Links:
Medium: https://medium.com/@sanish.abraham/designing-the-microservices-over-space-based-architecture-a41b107a79de
LinkedIn: https://www.linkedin.com/in/sanishabraham/
Keywords:
Microservice, Space Based Architecture, Container, Single DB, Cache, Central Database, Replicated Cache Engine, In-memory Data Grid, Virtualized Middleware, Process Grid, Message Grid, Deployment Manager, Data Writer, Data Reader, Persistent Message Queues, Data Pipelines, Monolith Database, Bounded Context, Service Domain, Data Decoupling, Database Decomposition, Command Query Request Segregation Pattern, Database Sharding, Horizontal Partitioning, Transactional Sagas, Orchestration Pattern, Choreography Pattern, Distributed Transactions
Hashtags:
#microservice #spacebasedarchitecture #transactionalsagas #inmemorycache #datagrids #pipeline #messagequeue #boundedcontext #virtualizedmiddleware #replicatedcache #monolith #monolithdb #microservices #sharding #partitioning #cqrs #distribuedtransaction #databasedecomposition #database #sqlserver #hazelcast #apacheignite #oraclecoherence #messagegrid #datagrid #deploymentmanager #processgrid #sql #linq #csharp #processingunit #datawriter #datareader

Comments
Post a Comment